Noise: A Flaw in Human Judgment by Daniel Kahneman, Cass R. Sunstein, and Olivier Sibony
WHAT IS NOISE? If two felons receive sentences of three years and seven years when they should both be sentenced to five, the difference is due to noise. The average of three and seven is indeed five, but justice has quite obviously not been served! It reminds me of the joke about the three statisticians on a hunt: the first one overshoots by a foot, the second one undershoots by a foot, and the third one says, “Got him!” In practice, errors of this sort don’t cancel out but add up, with regrettable repercussions.
Noise undermines credibility and trust. A defendant’s sentence should not depend on which judge the case happens to be assigned to, and yet it does. Whenever different judges make different decisions on identical data, there is noise in the system. The outcome also shouldn’t depend on the judge’s mood or the weather, and yet it does, which represents a single judge’s inconsistency. These two forms of noise apply to all areas of our lives involving human judgment: justice, health, child custody, immigration, hiring, patents, forecasting, insurance, and more. Human judgment is invariably bedeviled by noise.
It is also typically “biased.” Examples of bias would be a judge granting parole to five percent of the cases versus another judge granting it to 95 percent of the same cases. In other words, a tendency toward leniency or stringency is a bias. Discrimination on the basis of race or gender is another example of bias.
Lord Kelvin famously wrote that to understand something you need to be able to measure it. In Noise, academics Daniel Kahneman, Cass Sunstein, and Olivier Sibony synthesize a large existing literature on human and algorithmic decision-making to do exactly that: they provide crisp measurements and examples of error, breaking them down into noise and bias. While bias has dominated headlines, with allegations about racial biases in the criminal justice system — accentuated by our determination to acknowledge and adjust for centuries of racial discrimination — the authors show why noise is typically a much bigger problem.
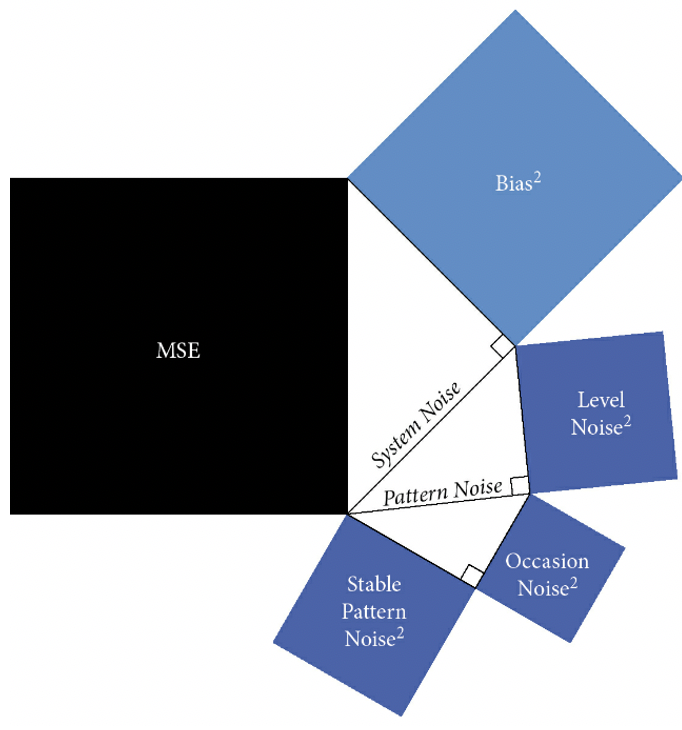
But how do we measure error? The authors point out that bias and noise are independent sources of error. They can be thought of as “orthogonal.” The math is easy and amounts to using the Pythagorean theorem, which readers may remember from high school geometry classes. Since errors can be positive and negative, as in the duck shoot, we can’t just average them and call it a day. Instead, we commonly square them first: the overall error equals bias squared plus noise squared. Think of a right triangle, with the orthogonal sides representing bias and noise, the latter typically longer, and the hypotenuse representing their combination.
The authors break down noise into “level noise” and “pattern noise” using the Pythagorean theorem. Level noise, which arises from bias, measures the variability in the average level of different judges’ judgments. Pattern noise arises from the variability in a single judge’s responses to particular cases, namely when they heavily weight a piece of data in a case that runs counter to their overall decision-making pattern. For example, a very lenient judge might be extremely severe toward recidivists whereas another might be harsh toward those who prey on the elderly. While some might argue that this isn’t noise but our ability to customize judgment to the specifics of a case, the larger point is that it adds uncertainty — noise — to the decision outcome.
The authors make a convincing case that pattern noise is pervasive in human judgment, and usually much higher — noisier — than level noise. Pattern noise arises, for example, in doctors’ decisions on whether to admit people for hospitalization, in insurance underwriting, in companies’ decisions on whom to hire, in the justice system, in decisions about which television shows to produce, and which investments to make. It arises from our desire to consider the individual nuances of a case when we deviate from our overall pattern as individuals.
It should not surprise us that pattern noise breaks down further into two independent sources: “stable pattern noise” and “occasion noise.” Stable pattern noise results from a judge weighing criteria in a case differently from another judge due to differences like personality, whereas occasion noise results from mood, weather, and other factors that depend on when a decision is made.
Here’s a complete pictorial decomposition of overall error, referred to here as Mean Squared Error (MSE), into bias and noise, and a breakdown of noise into level noise, stable pattern noise, and occasion noise:
Source: the authors
Noise also presents psychological reasons for why noise arises. This is useful for considering how we might lower or eliminate it. Should we replace these noisy systems with machines? Should we just take lots of human judgments and average them when possible, perhaps replacing individual judgment with the group’s average? Does plurality of views lead to better outcomes?
Not so fast, caution the authors. While groups might be useful when independent judgments are averaged, or in exposing multiple independent points of view, group decision-making is plagued with other sources of noise. We have all experienced meetings where the first person to speak influenced the final outcome. Groups are also subject to social pressure, with people wanting to be team players, which can lead to wide disparities among groups looking at the same situation and so to polarization.
So, should we give up on humans and train machines to make better and noise-free decisions instead? Is human complexity and variability — something we generally celebrate as being inherently human and positive — a liability when it comes to decision-making?
The authors aren’t willing to give up on humans just yet. They point to evidence that some humans are better decision-makers than others. Better “decision hygiene,” where people systematically follow a well-defined process, can lead to better and more consistent outcomes, they claim. They point to forecasting research by political scientist Philip Tetlock and his colleagues [1] suggesting that humans who are committed to self-improvement, not overconfident in their beliefs, and open to self-criticism and alternative views, tend to be better forecasters. Selecting and aggregating these “superior” humans into an ensemble can produce better decisions than those of the individuals.
The most actionable recommendation for managers and policy-makers is a “noise audit” designed to reveal their organizations’ most egregious areas of inconsistency. While low-noise cases where everyone with professional training reaches the same conclusion do indeed exist, the fact is that the important ones are prone to high decision variance. And yet, in most organizations, because of the rigidity of routines and the limits of time, judgments may never be evaluated against a true value, let alone vetted by another expert. That is a big mistake.
In practice, I suspect noise audits will be a lot more challenging in some fields, like justice, than others, like insurance. It is easier to determine whether two insurance applications are the same versus two crimes. While the authors acknowledge the organizational impediments of conducting noise audits, they are less comprehensive in recognizing the practical realities of comparing data across domains.
This book isn’t just for professionals. It should also change the way individuals evaluate their everyday decision-making and interactions. It made me acknowledge my own potential for inconsistency in grading, for example. It induced me to try and improve how I graded the 120 projects in my Systematic Investing class at NYU over the Memorial Day weekend, albeit not without cost in terms of time and effort. I graded each project twice to reduce my “occasion noise” (because I have a large number of students, I assumed that I would not remember my previous grade, which should provide some degree of independence to the two judgments). I also pressed my grader into service in an attempt to reduce pattern noise, and dig deeper into high-variance cases.
The authors also present compelling evidence that even simple mechanistic models usually do better than the best humans. Given an input, models will always make the same decision. While they might get flummoxed by so-called “edge cases,” that we might imagine would benefit from a fine-tuned human understanding of nuance or context, they still tend to account for the variability of individual cases better than humans. And as more data become available, enabling more complex AI models with higher accuracy and less bias, the case for machines over humans will become even more compelling. After all, quality and consistency are the bedrock of fairness, which we desire in our systems, especially those that operate at scale.
However, despite the evidence, the authors opine that algorithms are not a universal substitute for human judgment. “Universal” is a strong condition, and a straw man in fact: the real question is when or under what conditions we should substitute humans with machines, and when and how should we augment them. It leaves us with the tantalizing question of what the future roles of humans and machines in society will be as machines become smarter and more capable of auditing themselves, while humans remain relatively static in their abilities. I suspect that the nature of the problem, which includes the time pressure under which decisions are made as well as the consequences of errors, will have a major impact on such decisions.
How we divide and conquer our problems alongside intelligent machines will be the most important question going forward, and it is unanswered by the authors. A popular position bolstered by chess champion Garry Kasparov posits that humans plus machines are better than machines in terms of decision quality. Perhaps this belief is popular because it keeps humans in “control.” It is likely wishful thinking.
For example, imposing human judgment on a good algorithmic model in capital markets worsens performance. Humans tend to impose overly simplistic causal judgments such as, “The Fed will raise rates tomorrow, causing bonds to sell off, so the machine’s decision to buy bonds must be wrong. I would do the opposite.” Humans fail to consider the myriad other factors that go into the machine, which lacks the introspective ability to explain itself in simple terms that humans can digest.
The need for human control also undermines our justice and health-care systems. Humans feel that they are better able to account for the uniqueness of an individual in these contexts. And we, the individual in question, whether we are a patient of defendant, don’t want to be treated like cogs in an impersonal machine. But we are paying a heavy price: our current-day systems of judgment treat every case as a possible edge case, requiring human attention that is already at a deficit.
The question confronting us today is how do we reconcile our need for uniqueness with our desire for consistency and higher quality decisions. This is a question the book implicitly asks but, again, does not answer. And it is perhaps the most important question of all.
If we are to accept machine-based decision-making — a question of “when” and not “if” — the challenge lies in discriminating between the real edge cases and the rest, and reserving human attention for when it is truly needed. This is a hard problem, but there’s no getting away from it. I have written about why COVID-19 was a good example of an edge case in capital markets, [2] but it was very difficult to recognize it as such in the heat of the moment in the same way that it’s difficult — and nerve wracking — for a pilot to decide that autopilot has possibly become untrustworthy and it’s time to take control. In principle, a machine should know when it is at the edge of its capability, namely in an edge-case situation, and enable a human to take over gracefully. More and better instrumentation here would lead to better overall decisions by humans and machines.
Data scientists and AI people who are familiar with noise — typically in the form of an “error term” in predictive models — should also read this book. It will provide them with a more nuanced appreciation of patterns of noise in their training data, and its impacts on the properties of models that are learned by the machine. For example, problems with lower predictability imply higher noise in the training data; this means greater uncertainty about the worst-case behavior of predictive AI models and the associated costs of error, and so ends up determining the trustworthiness of AI systems.
One thing is certain. Noise will change how we think about human decision-making, and how we decide to accommodate machines. The stakes are large, and the book timely.
Vasant Dhar is a professor at the Stern School of Business, and director of Graduate Studies for the PhD program at the Center for Data Science at New York University. His research and practice is about the design of trustable prediction and decision-making machines, and how to govern the data that is used and created by such machines. He pioneered the use of machine learning in capital markets, and uses machines to trade professionally. Like other humans, he trusts his gut more than he should. Follow him on bravenewpodcast.com.
Did you know LARB is a reader-supported nonprofit?
LARB publishes daily without a paywall as part of our mission to make rigorous, incisive, and engaging writing on every aspect of literature, culture, and the arts freely accessible to the public. Help us continue this work with your tax-deductible donation today!
:quality(75)/https%3A%2F%2Fdev.lareviewofbooks.org%2Fwp-content%2Fuploads%2F2021%2F08%2Fnoise.jpeg)